Индекстрон против нейросети: в России создан метод мгновенного обучения при распознавании образов
Индекстрон против нейросети: в России создан метод мгновенного обучения при распознавании образов

Алгоритму «Индекстрон» (далее – индекстрон) достаточно одной фотографии, чтобы научиться узнавать искомый объект, в то время как искусственной нейронной сети для этого требуются тысячи изображений. Эксперименты ученых Института проблем управления им. В. А. Трапезникова РАН (ИПУ РАН) подтвердили, что даже после столь краткого «инструктажа» индекстрон успешно распознает объекты вне зависимости от их масштабирования и вращения и при значительных их деформациях.
Индекстрон – российское изобретение, аналогов которому в мире нет. Первую работу создатель этого алгоритма, старший научный сотрудник лаборатории «Технической диагностики и отказоустойчивости» к. т. н. Алексей Михайлов опубликовал еще в 1998 году. С тех пор этот алгоритм протестирован во множестве самых разных приложений: он анализировал сигналы гамма-телескопа, классифицировал растительность по спутниковым снимкам, осуществлял навигацию по изображениям лунной поверхности, а также нашел применение при идентификации отпечатков пальцев, при распознавании торговых знаков и даже проверял сочинения школьников. Теперь же специалисты ИПУ РАН испытали его в решении сложнейшей задачи – распознавание объектов, снятых с разных ракурсов, на разных расстояниях и на произвольном фоне.
Автоматическое распознавание трехмерных образов на плоских изображениях – сложная задача, которую сегодня решают с помощью искусственных нейронных сетей. Нейросети имитируют принцип работы нейронов мозга, однако сравниться с человеческим разумом в эффективности и быстродействии распознавания образов им пока не удается. Человек мгновенно отличает розу от кошки, а искусственной нейронной сети этому нужно долго учиться.
«Главная проблема, связанная с искусственными нейронными сетями, – это проблема обучения, – говорит Алексей Михайлов. – Для обучения, то есть адаптации нейронных сетей к разным приложениям, требуется найти большое количество коэффициентов, с помощью которых сеть настраивается на ту или иную задачу, а для нахождения этих коэффициентов нужен большой объем вычислений».
Эта проблема, по словам ученого, усугубляется сложностью выделения признаков, по которым распознается тот или иной объект. Раньше это делалось «вручную» методом проб и ошибок, то есть человек сам изобретал – какими признаками воспользоваться, чтобы распознать кошку. Это могли быть, например, длина ушей, полосы на шерсти, расстояние между глазами и т. д. После этого нейронную сеть настраивают с помощью коэффициентов на этот признак и смотрят на результат. Затем пробуют другой признак, и такой подбор может продолжаться достаточно долго. Это неудобно, поэтому 15 лет назад появилось так называемое глубокое машинное обучение, когда используется много слоев нейронов – 100 и даже больше, что позволяет работать с «сырыми» признаками – например, с пикселями изображенных объектов.
«При глубоком машинном обучении ничего не надо изобретать, – говорит Алексей Михайлов. – Алгоритм сам формирует критерии отбора на основе «сырых» признаков. Глубокое обучение сейчас очень популярно, но оно решает проблему автоматизации нахождения признаков за счет использования все большего числа коэффициентов. Ведь каждый слой – это новые коэффициенты».
Наконец, есть еще одна проблема: для обучения нейронной сети требуется огромный объем данных. Сеть должна проанализировать тысячи фотографий кошки, чтобы научиться узнавать ее. Предложенный российскими учеными алгоритм тоже работает с «сырыми» признаками в виде пикселей, но при этом ему не надо вычислять никаких коэффициентов и для обучения достаточно пары, а иногда и одной фотографии.
«Алгоритм представляет собой индексный классификатор, для краткости названный индекстроном, – рассказывает ученый. – Он использует тот же принцип работы, что и поисковик Google. Это очень простая и удобная штука, которую в дальнейшем можно реализовать в виде чипа».
Интересна родословная этого изобретения. Если нейронные сети происходят от перцептрона Розенблатта (кибернетическая модель мозга, реализованная в 1960 году в виде первого в мире нейрокомпьютера «Марк-1» американским ученым Фрэнком Розенблаттом), то индекстрон и его близкий родственник поисковик Google происходят от книжного индекса, того самого, который можно найти в конце некоторых книг, где по ключевым словам можно сразу отыскать страницу, где они встречаются.
Индексный поиск в Google осуществляется за счет работы с обратными документами. Документ – это множество слов, а обратный документ – это список документов, в которых встречается ключевое слово, набранное в поисковой строке, после чего Google практически мгновенно выдает ссылки на все заранее проиндексированные документы, в которых встречается слово или несколько слов из поискового запроса.
«Индекстрон работает очень похоже, но если поисковик Google работает с текстовой информацией, то индекстрон – с числами», – поясняет Алексей Михайлов.
Любое изображение можно считать документом, состоящим не из слов, образующих предложения, а из графических элементов, складывающихся в образ. Слово состоит из букв, а графический образ – из пикселей. Каждый пиксель можно представить в цифровом виде, где каждый из его цветов – красный, зеленый и синий – имеет 256 уровней яркости. Таким образом каждый пиксель переводится в три числа, и дальше индекстрон работает с этими данными.
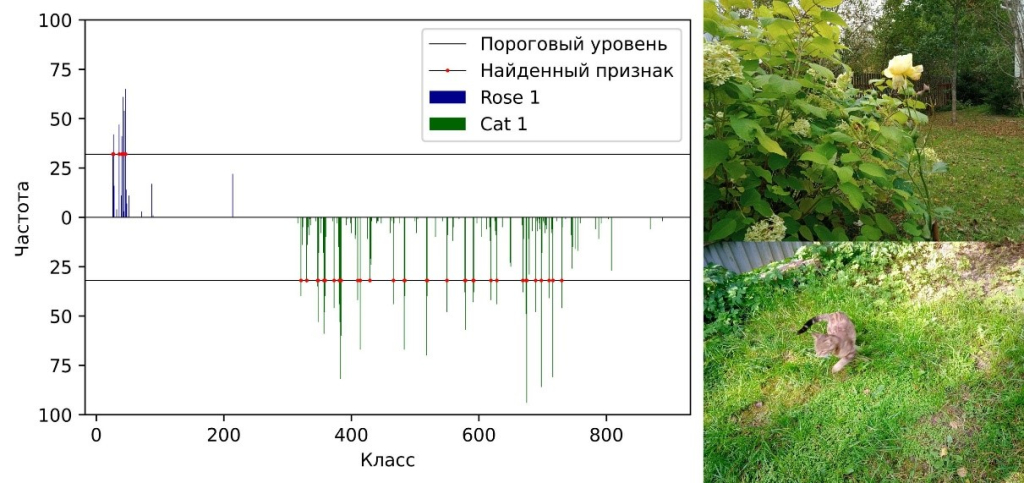
Рис. 1. Справа две фотографии объектов Rose и Cat, на которых проводилось обучение индекстрона. Алгоритм переводит пиксели в цифровой вид по красной, зеленой и синей составляющей цвета каждого пикселя, а затем выделяет классы пикселей, которые характеризуют эти объекты. Частота, с которой встречаются на изображении пиксели этих классов, служит признаком распознавания. На гистрограмме слева видно, насколько разительно отличаются распределения частот классов для данных двух объектов.
В упрощенном виде работа индекстрона выглядит так: образ кошки характеризуется определенным набором пикселей, так же как слово «кошка» характеризуется определенным набором букв. Индекстрон может по одной фотографии, на которой есть кошка, выделить характеризующий ее образ набор чисел. Обучение происходит практически мгновенно. И если на другой фотографии встречается такой же характерный набор чисел, то индекстрон опознает в нем кошку.
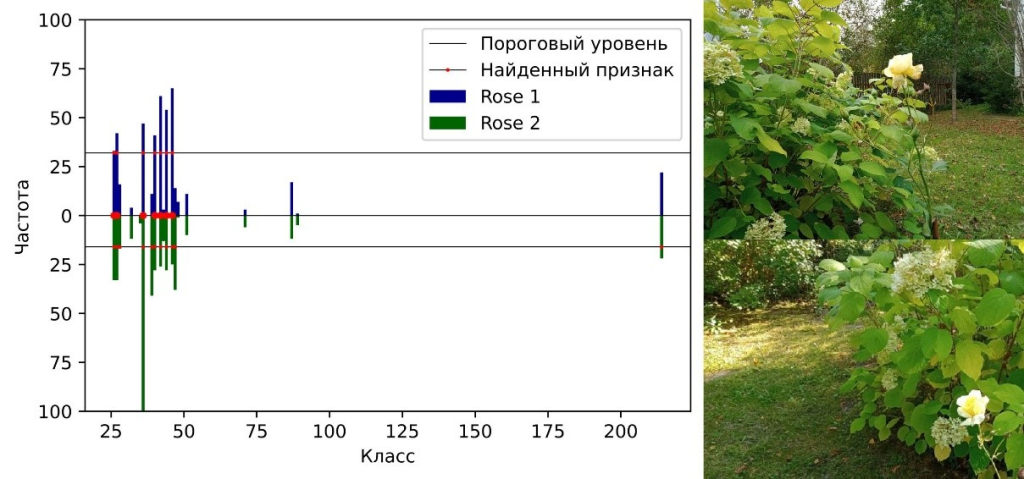
Рис. 2. Сравнение «цифровых подписей» объекта Rose на снимках, сделанных с разных ракурсов. Количество общих признаков равно 7.
Поисковик Google не думает о смысле слова «кошка», он просто индексирует документы, его содержащие. Но индекстрон индексирует не изображения, а объекты с помощью характеризующих искомые образы наборов цифр. Поэтому не имеет значения, какое изображение будет предъявлено системе. Если изображение содержит кошку, она будет распознана. Таким образом, поисковая машина становится распознающим устройством.
«Мозг человека состоит из рассудочной и эмоциональной частей, – говорит Алексей Михайлов. – Рассудок находится в коре головного мозга, а эмоции – в мозговом стволе в его центре, но мозг – это не компьютер. Он не занимается вычислениями. Есть предположение, что именно индексация образов, а не вычисления лежат в основе биологических распознающих систем, и кора головного мозга – это индексная система, в которой образы описываются по комбинации адресов. Этим и объясняется быстродействие мозга в задачах распознавания образа. Нейроны мозга работают с частотой ниже 500 Гц, в то время как тактовая частота компьютеров достигает миллиардов герц – нескольких МГц, но все равно мозг начинает узнавать незнакомого человека с первой встречи, то есть он может мгновенно обучаться».
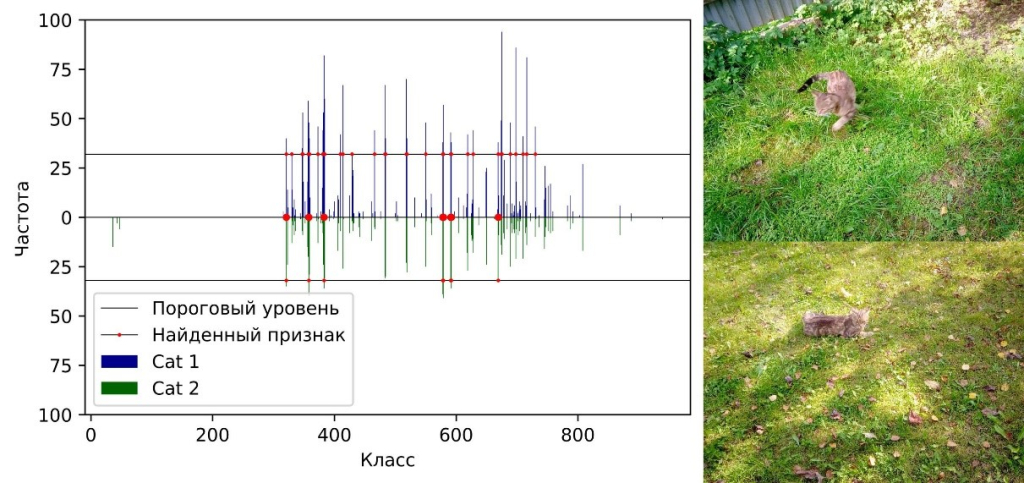
Рис. 3. Сравнение «цифровых подписей» изображений объекта Cat на разных фотографиях. Количество общих признаков равно 6. Объект распознается несмотря на другой ракурс, положение тела и поджатый хвост.
Индекстрон был обучен на двух разных объектах (цветок и кошка). Причем обучение было проведено с использованием только двух изображений. Для тестирования те же объекты были показаны под другими ракурсами: 10 000 тестовых изображений классифицировались с использованием четырехслойной нейронной сети и индекстрона.
Чтобы научить четырехслойную нейронную сеть узнавать на изображении кошку или розу, потребовалось 900 с. При этом помимо процессора AMD Ryzen 5 3600 использовалась видеокарта Nvidia GeForce GTX 1600 Super. На обучение индесктрона ушло всего 16 с. При этом применялся тот же процессор, но без видеокарты. В результате четырехслойная нейронная сеть показала точность идентификации объекта 85,3 %, а индекстрон – 82,87 %.

Рис. 4. Возможности индекстрона были проверены и при распознавании таких объектов, как автомобиль. Слева – фотография, на которой проводилось обучение. Справа – тестовая фотография. Автомобиль был распознан несмотря на совершенно другой ракурс.
Результаты эксперимента позволяют говорить о том, что общей чертой как индекстрона, так и глубокого обучения нейронных сетей является автоматическое формирование признаков, что существенно снижает трудоемкость проектирования систем распознавания образов. Вместе с тем производительность индекстрона при обучении намного выше.
Но главное преимущество индекстрона – простота его практического применения. Время и энергозатраты, требуемые для обучения систем распознавания на основе нейронных сетей при решении крупных задач, приводят к необходимости использования облачных технологий и высокопроизводительных машинных станций. В случае использования индекстрона простота алгоритма позволяет реализовать его всего на одной программируемой логической интегральной микросхеме с памятью 1,44 МБ. Аппаратная реализация индекстрона делает возможным его использование для различных автономных устройств, где требуется мгновенная реакция, в том числе мгновенное обучение при возникновении новых ситуаций.
Подробнее см. в статье «Мгновенное обучение при распознавании образов», А. М. Михайлов, М. Ф. Каравай, В. А. Сивцов, «Автоматика и телемеханика», № 3, 2022.
Подготовил Леонид Ситник, редакция сайта РАН.
Фото авторов исследования и Pixabay/GDJ